Golang中的调度器
admin
- One minute read - 131 words
golang实现的协程调度器,其实就是在维护一个G、P、M三者间关系的队列。
介绍(Introduction) ——————— Go 1.1最大的特色之一就是这个新的调度器,由Dmitry Vyukov贡献。新调度器让并行的Go程序获得了一个动态的性能增长,针对它我不能再做点更好的工作了,我觉得我还是为它写点什么吧。
这篇博客里面大多数东西都已经被包含在了[原始设计文档]( https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw)中了,这个文档的内容相当广泛,但是过于技术化了。
关于新调度器,你所需要知道的都在那个设计文档中,但是我这篇博客有图片,所以更加清晰易懂。
带调度器的Go runtime需要什么?(What does the Go runtime need with a scheduler?) ——————————————————————————- 但是在我们开始看新调度器之前,我们需要理解为什么需要调度器。为什么既然操作系统能为我们调度线程了,我们又创造了一个用户空间调度器?
POSIX线程API是对现有Unix进程模型的一个非常大的逻辑扩展,而且线程获得了非常多的跟进程相同的控制。比如,线程有它自己的信号掩码,线程能够被赋予CPU affinity功能(就是指定线程只能在某个CPU上运行),线程能被添加到cgroups中,线程所用到的资源也可以被查询到。所有的这些控制增大了Go程序使用goroutine时根本不需要的特性(features)的开销,当你的程序有100,000个线程的时候,这些开销会急剧增长。
另外一个问题是,基于Go模型,操作系统不能给出特别好的决策。比如,当运行一次垃圾收集的时候,Go的垃圾收集器要求所有线程都被停止而且要求内存要处于一致状态(consistent state)。这个涉及到要等待全部运行时线程(running threads)到达一个点(point),我们事先知道在这个地方内存是一致的。
当很多被调度的线程分散在随机的点(random point)上的时候,结果就是你不得不等待他们中的大多数到达一致状态。Go调度器能够作出这样的决策,就是只在内存保持一致的点上进行调度。这就意味着,当我们为垃圾收集而停止的时候,我们只须等待在一个CPU核(CPU core)上处于活跃运行状态的线程即可。
来看看里面的各个角色(Our Cast of Characters) —————————————– 目前有三个常见的线程模型。一个是N:1的,即多个用户空间线程运行在一个OS线程M上。这个模型可以很快的进行上下文切换,但是不能利用多核系统(multi-core systems)的优势。另一个模型是1:1的,即可执行程序的一个线程匹配一个OS线程M。这个模型能够利用机器上的所有核心的优势,但是上下文切换非常慢,因为它不得不陷入OS(trap through the OS)。
Go试图通过M:N的调度器去获取这两个世界的全部优势。它在任意数目的OS线程M上调用任意数目的goroutines G。你可以快速进行上下文切换(P角色),并且还能利用你系统上所有的核心的优势。这个模型主要的缺点是它增加了调度器的复杂性。
为了完成调度任务,Go调度器使用了三个实体:
[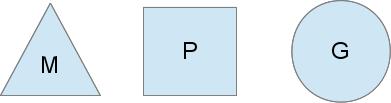
三角形M 表示OS线程,`它是由OS管理的可执行程序的一个线程`,就是平常提到的操作系统中的线程,而且工作起来特别像你的标准POSIX线程。在运行时代码里,它被成为M,即机器(machine)。
圆形G 表示一个goroutine。它包括栈、指令指针以及对于调用goroutines很重要的其它信息,比如阻塞它的任何channel。在可执行代码里,它被称为G。
矩形P 表示用于调用的上下文。你可以把它看作在一个单线程上运行代码的调度器的一个本地化版本。它是让我们从N:1调度器转到M:N调度器的重要部分。在运行时代码里,它被叫做P,即处理器(processor)。这部分后面会多说点。
[
我们可以从上面的图里看到两个系统线程(M),每个线程都拥有一个上下文(P),每个线程都正在运行一个goroutine(G)。为了运行goroutines,一个线程必须拥有一个上下文。
上下文(P)的数目在启动时被设置为环境变量GOMAXPROCS的值或者通过运行时函数GOMAXPROCS()来设置。通常,在你的程序执行时它不会发生变化。上下文的数目被固定的意思是,只有GOMAXPROCS个上下文正在任意点上运行Go代码。我们可以使用GOMAXPROCS调整Go进程的调用使其适合于一个单独的计算机,比如一个4核的PC中可以在4个线程上运行Go代码。
外部的灰色goroutines没在运行,但是已经准备好被调度了。它们被安排成一个叫做runqueue的列表。当go创建一个goroutine的时候,goroutine就被添加到runqueue的末端。一旦一个上下文已经运行一个goroutine到了一个点上,它就会把一个goroutine从它的runqueue给pop出来,设置栈和指令指针并且开始运行这个goroutine。
为了降低mutex竞争,每一个上下文都有它自己的runqueue。Go调度器曾经的一个版本只有一个通过mutex来保护的全局runqueue,线程们经常被阻塞来等待mutex被解除阻塞。当你有许多32核的机器而且想尽可能地压榨它们的性能时,情况就会变得相当坏。
只要所有的上下文都有goroutines要运行,调度器就能在一个稳定的状态下保持调度。但是有几个你能改变的场景。
通俗地讲,G要运行,需要绑定一个P(放在P的本地队列里),然后由与P绑定的操作系统线程M真正执行。 G切换时,只是M从G1切到G2而已,都是在用户态进行着,非常轻量,不像操作系统切换M时比较重。
你打算(系统)调用谁?(Who you gonna (sys)call?)
——————————————————
你现在可能想知道,为什么一定要有上下文?我们能不能丢掉上下文而仅仅把runqueue放到线程上?不尽然。我们用上下文的原因是如果正在运行的线程因为某种原因需要阻塞的时候,我们可以把这些上下文移交给其它线程。
我们需要阻塞的一个例子是,当我们需要调用一个系统调用的时候。因为一个线程不能既执行代码同时又阻塞到一个系统调用上,我们需要移交给对应于这个线程的上下文,以让这个上下文进行调度。
[
从上图我们能够看出,一个线程放弃了它的上下文以让另外的线程可以运行它。调度器确保有足够的线程来运行所有的上下文。上图中的M1 可能仅仅为了让它处理图中的系统调用而被创建出来,或者它可能来自一个线程池(thread cache)。这个处于系统调用中的线程将会保持在这个导致系统调用的goroutine上,因为从技术上来说,它仍然在执行,虽然阻塞在OS里了。
当这个系统调用返回的时候,这个线程必须尝试获取一个上下文来运行这个返回的goroutine,操作的正常模式是从其它所有线程中的其中一个线程中“偷”一个上下文。如果“偷盗”不成功,它就会把它的goroutine放到一个全局runqueue中,然后把自己放到线程池中或者转入睡眠状态。
这个全局runqueue是各个上下文在运行完自己的本地runqueue后用来获取新goroutine的地方。上下文也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
`Go程序要在多线程上运行的原因就是因为要处理系统调用,哪怕GOMAXPROCS等于1`。运行时(runtime)使用调用系统调用的goroutines,而不是线程。
盗取工作(Stealing work) —————————– 系统的稳定状态改变的另外一个方法是,当一个上下文运行完要被调度的所有goroutines的时候。如果各个上下文的runqueue里的工作的数目不均衡,改变就会发生了,否则会导致一个上下文在执行完它的runqueue后就会结束,尽管系统中仍然有许多工作要执行。所以为了保持运行Go代码,一个上下文能够从全局runqueue中获取goroutines,但是如果全局runqueue中也没有goroutines了,那么上下文就不得不从其它地方获取goroutines了。
[
这个“其它地方”指的是其它上下文!当一个上下文完成自己的任务后,它就会尝试“盗取”另一个上下文runqueue中工作量的 一半。这将确保每个上下文总是有活干,然后反过来确保所有线程尽可能处于最大负荷。
下一步走向何方?(Where to go?) ————————————– 关于调度器还有许多细节,像cgo线程、LockOSThread()函数以及与网络poller的整合。这些已经超过这篇文章的要探讨的范围了,但是仍然值得去研究。以后我会针对这些再写点文章。在Go运行时库里,仍然有大量有意思的创建工作要做。
By Daniel Morsing
(end)
英文原文: http://morsmachine.dk/go-scheduler
G-P-M调度模型
Golang能够拥有强大的并发能力需要归功于G-P-M调度模型,首先需要解释G、P、M分别代表什么:
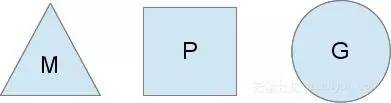
- G 代表Goroutine,每个Goroutine对应一个G结构体,G存储Goroutine的运行栈、状态以及任务信息,可重用。Goroutine栈采用按需动态分配的方式,初始化大小为2KB,最大为1GB(64位机器)。
- P 代表Processor,逻辑处理器。P维护Goroutine各种队列,mcache和状态。P的数量决定了最大可并行的Goroutine数量(前提:系统物理CPU核数>=P数量)。P的数量可以通过GOMAXPROCS设置。但是不能超过256,超过256会设置为256。
- M 代表内核级别线程,一个M就是一个线程。默认最大限制为10000个。
golang实现的协程调度器,其实就是在维护一个G、P、M三者间关系的队列。
golang的m:n线程模
golang采用了m:n线程模型, 即m个gorountine(简称为G)映射到n个P,每个P对应一个内核态线程(简称为M)。
[
底层实现
从图中可以得知goroutine是用户态协程,有时间我们也叫做用户态线程,要区别与内核态线程,这点务必清楚理解。
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor。任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。
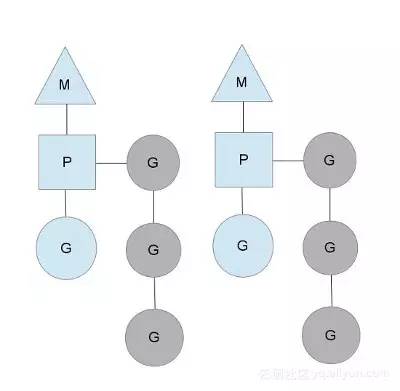
多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
线程阻塞
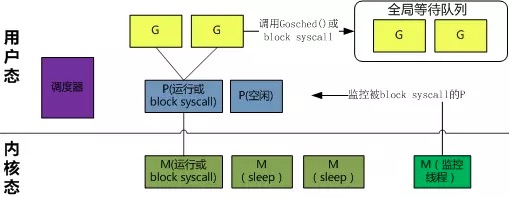
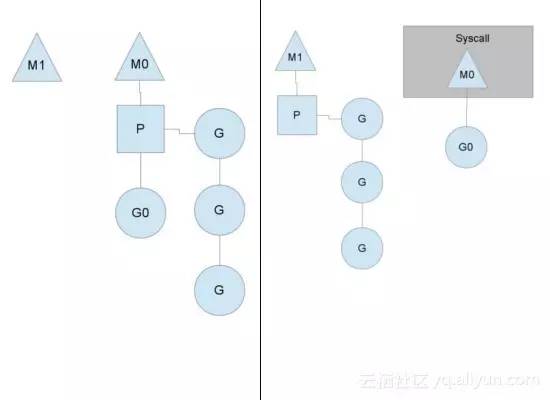
从图中可以看出,一共有两个物理线程M,每个M都绑定一个处理器P,每个P维护一个就绪状态的Goroutine队列,灰色的表示在等待P调度,蓝色的G代表正绑定P在M中执行。当执行go func时,会将创建的Goroutine挂载在灰色的等待队列中。
当执行的Goroutine(G0)调度阻塞的系统调度时,P会切到另外的M’中,如果没有可用的M’就会创建一个,继续执行队列中的G。待系统调用返回时M0会重新绑定可用的P,如果没有可用的P就会把G0放到Global队列中,然后自己进入休眠。所有的P会周期性的检查Global队列,并且执行其中的G。如下图所示:
runqueue执行完成
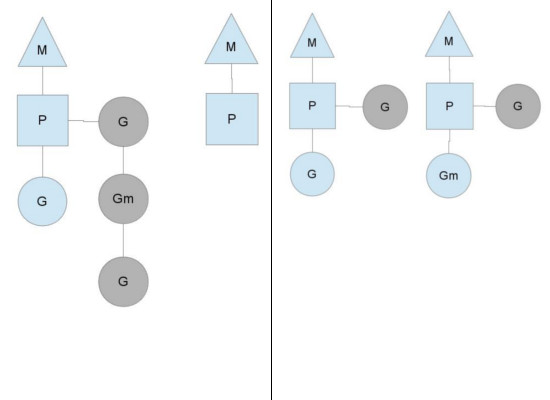
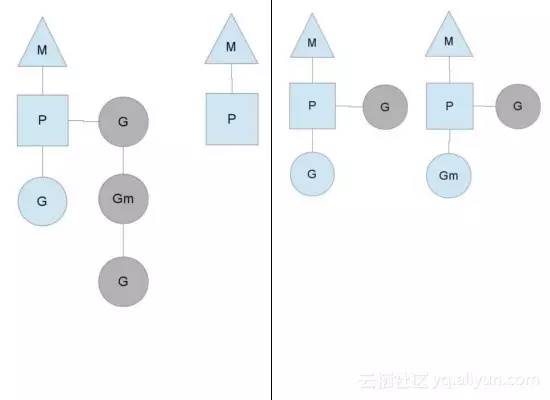
当一个P分配的G全部执行完时,P会先看**Global runqueue**是否还有G待执行;如果没有再再去检查网络轮询器是否有G待处理;如果仍没有再到其他P的 local runqueue中偷G,见 源码。一般都会偷走一半,确保操作系统的每个M都能得到充分利用。
例如下图中的第二个P没有G可以执行,所以把第一个P的Gm和G偷过来执行。
五、对并发实现的进一步思考
Go语言的并发机制还有很多值得探讨的,比如Go语言和Scala并发实现的不同,Golang CSP 和Actor模型的对比等。
了解并发机制的这些实现,可以帮助我们更好的进行并发程序的开发,实现性能的最优化。
参考:
- 深度解密Go语言之scheduler https://mp.weixin.qq.com/s/rpCf5vm9xYFXjmR98vanfQ
- https://www.jianshu.com/p/91e40c3e3acb
- https://www.cnblogs.com/sunsky303/p/9115530.html
- https://blog.csdn.net/heiyeshuwu/article/details/51178268
- https://my.oschina.net/SysuHuyh5LoveHqq/blog/876673
- http://morsmachine.dk/go-scheduler