Protobuf协议实现原理
admin
- 2 minutes read - 348 wordsprotobuf是Google开源的一款支持跨平台、语言中立的结构化数据描述和高性能序列化协议,此协议完全基于二进制,所以性能要远远高于JSON/XML。由于出色的传输性能因此常见于微服务之间的通讯,其中最为著名的是Google开源的 gRPC 框架。
那么protobuf是如何实现高性能的,又是如何实现数据的编码和解码的呢?
protobuf协议原理
基于128bits的数据存储方式(Base 128 Varints)
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分;如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:
1010 1100 0000 0010。
另外如果从数据大小角度来看,这种表示方式比真正要代表的数据多了一个bit, 所以其实际传输大小就多14%(1/7 = 0.142857143),对于这一点我们需要有所了解。
下面我们看一个例子:
数字1表示方式:0000 0001
对于小的数据比较好理解,正常情况下1的二进制是 0000 0001,使用128bits表示的话,首位结束标识位也是0,所以两者结果是一样的 000 0001。
上面是对小数据(<=128)的表示方法,我们再看一下非小数据(>128)的表示方法
数字 300 表示方式:1010 1100 0000 0010
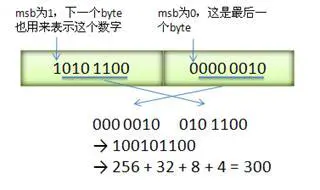
图中的 MSB(most significant bit )翻译过来就是最高有效位,有时候也称为 符号位(sign bit),如果值为 0 则表示当前 byte 为表示数字的最后一个字节。
这个有点不太好理解,这是因为原本用一个字节(8bit)就可以表示,但由于使用 128bits 表示方法,需要对每个字节的最高位添加一个 结束标识位 来表示,所以一个字节已经不够用了,需要占用两个字节来表示,每个字节的最高位是结束标识位。
如果正向推算的话,我们知道数字300的二进制值 1 0010 1100,用两个字节表示完整值则为
0000 0001 0010 1100 # 二进制
_000 0010 _010 1100 # 二进制每个字节的最高位向左移动一个位置,放入结束标识位
000 0010 1010 1100 # 转换为128bits方式,1:结束,0:未结束
1010 1100 000 0010 # 转换为 小端字节序, 低字节在前,高字节在后
这里为先添加结束标识符,然后再转为小端字节序,可以看到最终的数据与上图绿色框中的数字正好一样,这个正是数值 300 的 128bits 的表示法。当客户端读取到这个二进制后,再反向解析就是原来的数值 300 了。
协议数据结构
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。其中 Value 上面已介绍过,这里重点介绍 Key。如下图所示:
图 7. Message Buffer
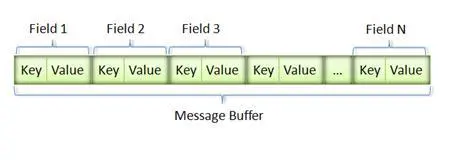
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。
对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
Key 用来标识具体的 field,在解包的时候,客户端创建一个结构对象,Protocol Buffer 从数据流中读取并反序列化数据,并根据 Key 就可以知道相应的 Value 应该对应于结构体中的哪一个 field。
而Key也是由以下两部分组成
Key 的定义如下:
1 (field_number << 3) | wire_type
可以看到 Key 由两部分组成:
第一部分是 field_number
第二部分为 wire_type,表示 Value 的传输类型
一个字节的低3位表示数据类型,其它位则表示字段序号。
Wire Type 可能的类型如下表所示:
表 1. Wire Type
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimi | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | Groups (deprecated) |
| 4 | End group | Groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
message Test1 {
required int32 a = 1;
}
在这个例子中,field id 所采用的数据类型为 int32,因此对应的 wire type 为上表中 0。细心的读者或许会看到在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型,Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。
每个数据头同样采用128bits方式,一般1个字节就足够了, 本例中字段 a 的 field_number=1。
如果创建了 Test1 的结构并且把 a 的值设为 2,序列化后的二进制数据为
0 000 1000 0 000 0010
将这个进制分散成 k:v 形式,则为
key 部分是 0000 1000 (第一个字段且wire_type为0)
value 部分是 0000 0010 (值即为10进制的2)
key的解释:
对于 key 协议规定数据头的低3位表示 wire_type, 其它字段表示字段序号field_number,因此
0000 1000
_000 1000 # 去掉结束标识符位
_000 1000 # 后三位 000 表示数据类型, 这里是Varint 数据类型
_000 1000 # 其它位 _000 1 这四位表示 filed_number,这里表示第 1 个字段
最后得出二进制 key部分 0 000 1000 表示第1个字段,类型为 Varint, 这里对应的是golang中的 int32 数据类型。
推荐阅读
- https://grpc.io/docs/languages/go/quickstart/
- https://blog.csdn.net/xuduorui/article/details/78278808
- https://grpc.io/docs/languages/go/quickstart/
- Protocol Buffers proto3 编程指南
- Proto Style Guide
- https://cloud.google.com/apis/design/custom_methods?hl=zh-cn
- protoc-gen-validate (PGV) 验证器
参考
- https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
- https://protobuf.dev/programming-guides/encoding/
- https://www.ruanyifeng.com/blog/2022/06/endianness-analysis.html