Runtime:源码解析Golang 的map实现原理
admin
- 16 minutes read - 3403 wordsgo version 1.15.6
map作为一种常见的 key-value 数据结构,不同语言的实现原理基本差不多。首先在系统里分配一段连接的内存地址作为数组,然后通过对map键进行hash算法(最终将键转换成了一个整型数字)定位到不同的桶bucket(数组的索引位置),然后将值存储到对应的bucket里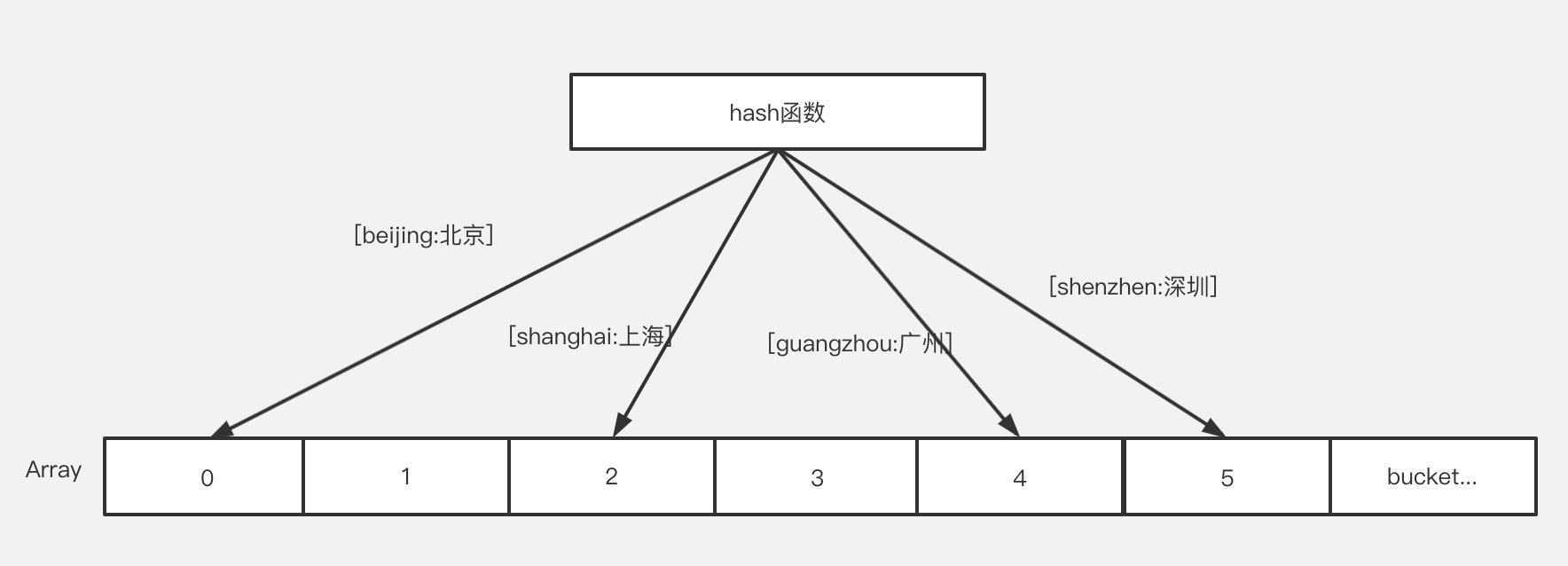
理想的情况下是一个bucket存储一个值,即数组的形式,时间复杂度为O(1)。
如果存在键值碰撞的话,可以通过 链表法 或者 开放寻址法 来解决。
链表法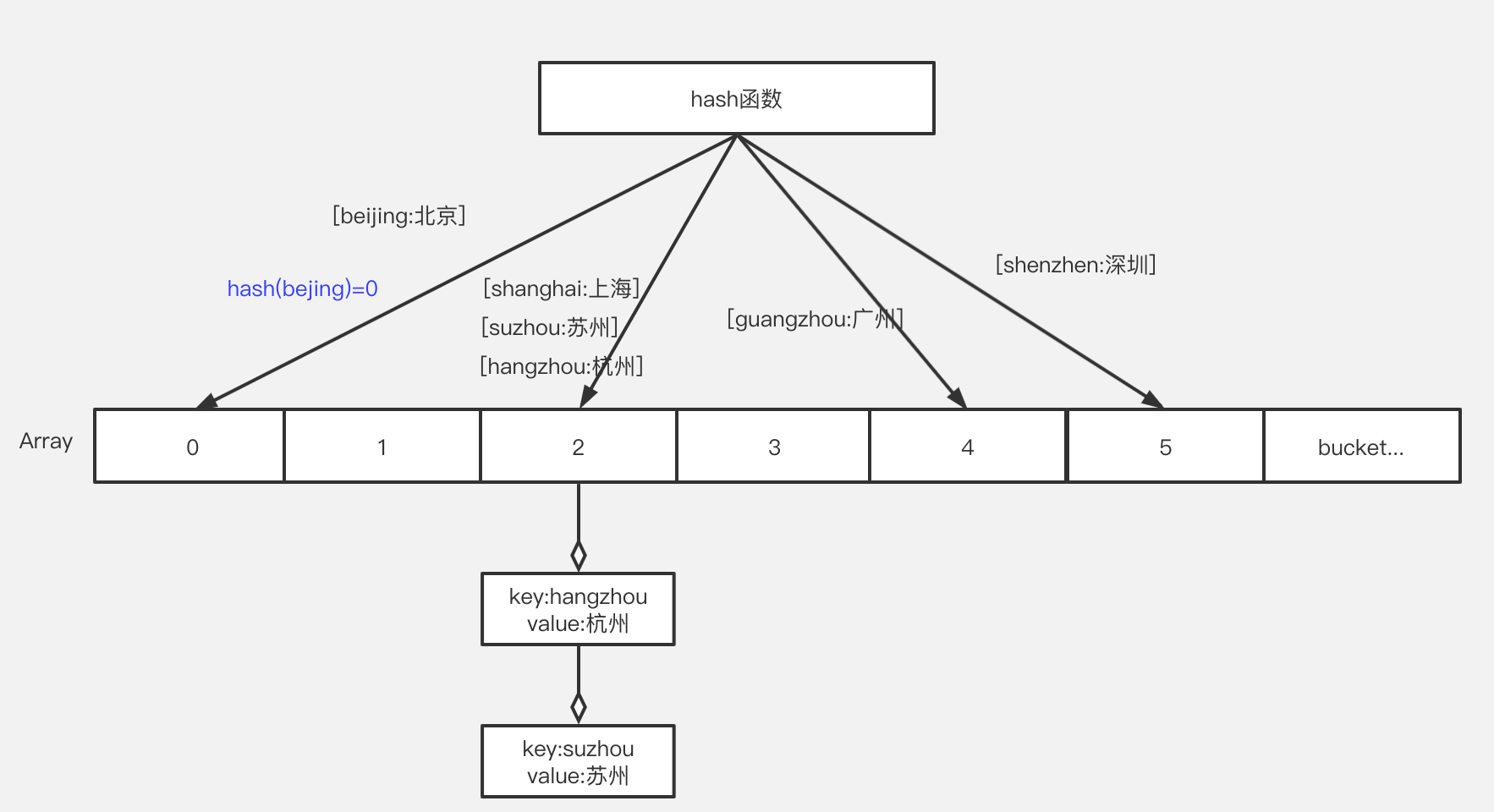
开放寻址法
对于开放寻址法有多种算法,常见的有线性探测法,线性补偿探测法,随机探测法等,这里不再介绍。
map基本数据结构
hmap结构体
map的核心数据结构定义在 /runtime/map.go
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
在源码中表示 map 的结构体是 hmap,即 hash map 的缩写。
count 指的是当前map的大小,即当前存放的元素个数,必须放在第一个位置,因为通过 len() 函数时,会通过 unsafe.Poiner 从这里读取此值并返回
flags 可以理解为一个标记位,几种值的定义( 这里),在多个地方需要使用此值,如 [mapaccess1()](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L410-L412)。
B 是一个对数,表示当前map持有的 buckets 数量(2^B)。但需要考虑一个重要因素装载因子,所以真正可以使用的桶只有loadFactor * 2^B 个,如果超出此值将触发扩容,默认装载因子是6.5
noverflow 溢出buckets数量
hash0 hash种子,在操作键值的时候,需要引入此值加入随机性
buckets 底层数组指针,指向当前map的底层数组指针
oldbuckets 同是底层数组指针,一般在进行map迁移的时候,用来指向原来旧数组。只有迁移过程中此字段才有意义,此字段数组大小只有buckets 的一半
nevacuate 进度计算器,表示扩容进度,小于此地址的 buckets 迁移完成
extra 可选字段,溢出桶专用,只要有桶装满就会使用
mapextra结构体
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
当 map 的 key 和 value 都不是指针且内联时,将会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,我们看到 bmap 有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
overflow 和 oldoverflow 只有当键和值不包含指针才使用,其中overflow存储hmap.buckets的溢出桶,而oldoverflow存储hmap.oldbuckets的溢出桶。
间接允许将指向切片的指针存储在hiter中
nextOverlflow 指向下一个空的溢出桶的指针
bmap结构体
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
bmap即bucket map的缩写。
这里只有一个tophash字段,是一个长度为 8 的数组,实际上在使用中值的类型是不固定的,甚至可以是一个自定义结构体的指针类型。这个结构体看起来可能有点让人费解,其实编译器在编译期间会动态创建一个新的同名数据结构,如下
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
每个桶里有 0-7 共八个存储位置,也就是说每个桶最多可以存储8个元素,其中将所有的键放在一起,按先后顺序存放在一个keys字段中,再将所有的值按同样的顺序放在一起存放在values字段中(注意:没有将每个键值单独存储在一个字段中,主要是为了解决内存对齐带来的浪费问题。)
例如 map[int64]int8 ,如果按 key/value/key/value/... 这种方式存储的话,则在每一个key/value之后需要padding 7 个字节才行。而如果按上面 key/key/key/... 和 value/value/value/... 这种方式的话,只需要在最后一个值的后面进行一次padding就可以了,大大节省了内存开支。如果不太懂这一块的话,可以了解一下golang的内存对齐。
如果当前bucket已满的话,则会创建新的bucket,并使用 overflow 字段进行bucket之间的连接,实现单向链表功能。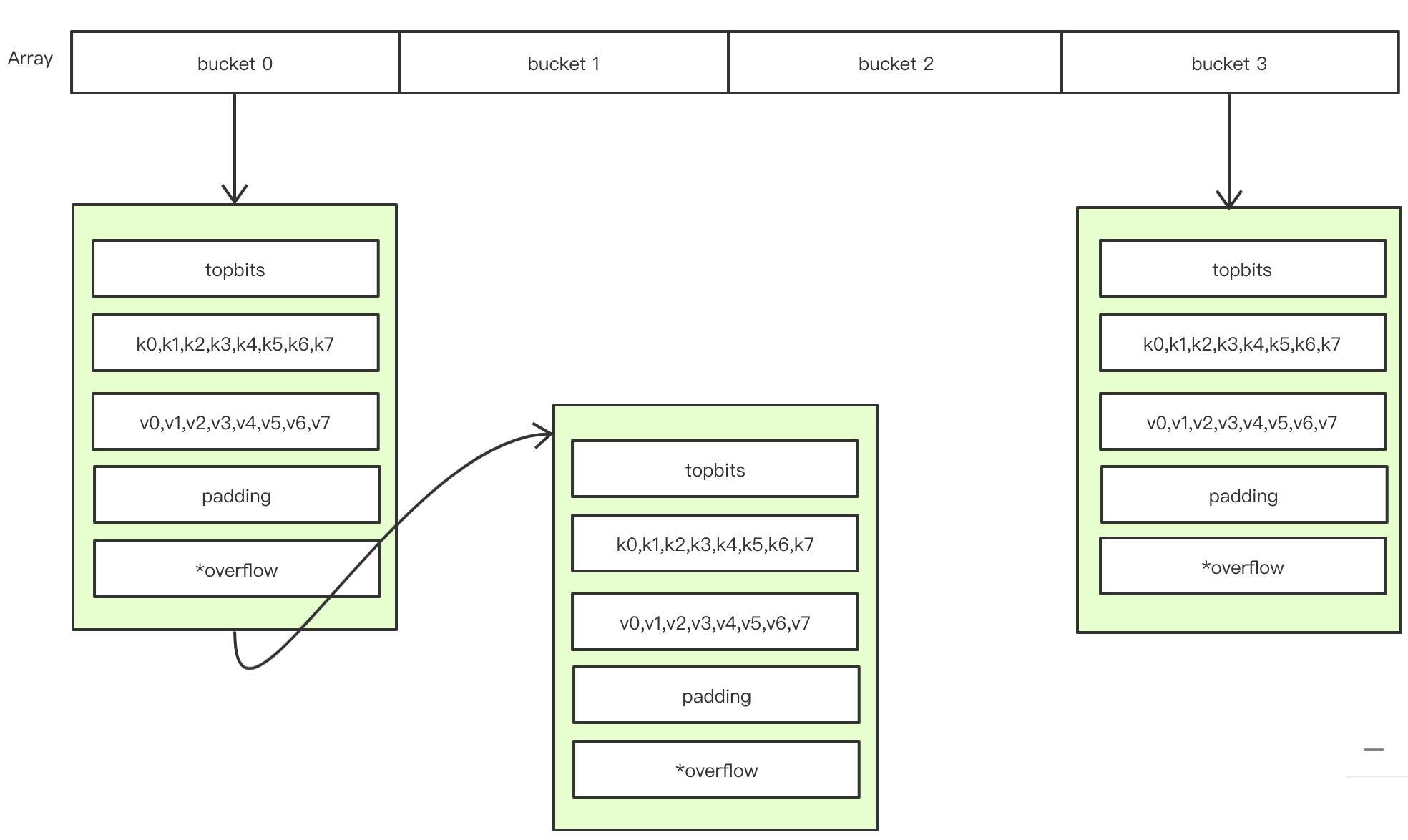
map结构体关系图
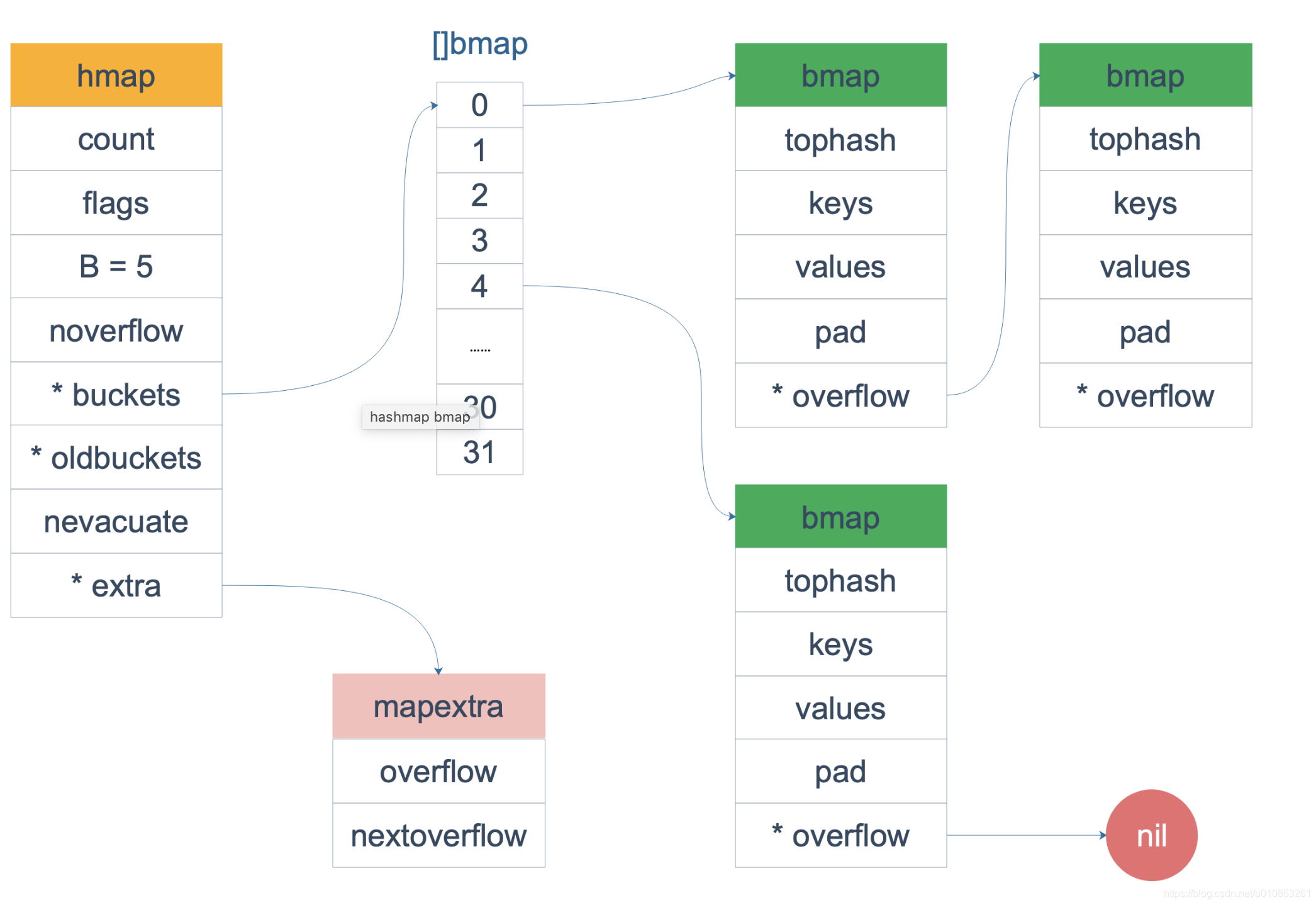 来源网络
来源网络
key的定位算法
在map中要存储一个键值对,必须先找到所在的位置,一般采用hash算法即取模的结果来实现,这里我们主要介绍一下map中是如何实现的。
在此这前先介绍一下map装载相关的内容。上面我们介绍 bmap 结构体的时候,有一个 B 字段,这个字段决定了map对应的底层数组的大小,它的大小决定了可以容纳的bucket的个数。如果B=5的话,则可以bucket的数组元素值个数为 2^5=32个,但golang中需要考虑到装载分子6.5这个因素,所以真正装载的元素并没有这么多。每当一个map存储的元素个数占比达到65%的时候,就会触发map的扩容操作。
如果想知道一个key要放在哪个bucket, 需要先计算出一个hash值,然后再除以 32取余数即可。golang 也是如此实现的,只不过是为了性能考虑,使用了位操作而已。如5 *2 换作用位操作的话,就是将5左移1位即可。也就是主每左移1位一次就是*2,左移两位就是*4,同理右移则是相除。
假如 hash(key) 计算出的结果为
10010111 | 000011110110110010001111001010100010010110010101010 │ 00110
根据上面得知 h.B = 5,则取后面的5位 00110,值为6,则需要将key:value存放在第6号的bucket中。
找到了要存储的桶位置,还需要找到放在桶的什么位置,每个位置我们可以称之为slot或者Cell。
// src/runtime/map.go
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
......
}
这里定义了一个bucket最多存放元素个数的相关常量,在go里一个bucket最多可以存放 2^3=8个 元素,再多的话就需要使用到溢出桶overflow。
slot位置计算公式为取hash的高8位,计算函数为 tophash()。这里高8位是 10010111,十进制的值为151, 于是在第6号bucket中遍历每个slot,直到找到bmap.tophash值为151的slot,当前slot在bucket中的索引位置就是要找的键和值的索引位置。然后根据当前位置索引值分别从bmap.keys和bmap.values中计算出对应的值。
如果当前bucket中没有找到,就去当前bucket 中的溢出桶overflow中查找,如果overflow为nil,则直接返回空值即可。
总结
要想实现元素的存储定位需要三个步骤:
- 根据
h.B的值取出hash结果的最后b.B位数字(低位),定位到bucket - 再根据hash结果的
高8位,定位到在bucket中存储的位置 - 最后根据位置分别从
bmap.keys和bmap.values中读取存储的值内容
map创建
package main
func main() {
m := make(map[int]string)
m[0] = "a"
_ = m[0]
_, _ = m[0]
delete(m, 0)
}
我们先看一下与 map 相关的runtime有哪些
$ go tool compile -S main.go | grep runtime
0x0080 00128 (main.go:4) CALL runtime.fastrand(SB)
0x00aa 00170 (main.go:5) CALL runtime.mapassign_fast64(SB)
0x00bc 00188 (main.go:5) CMPL runtime.writeBarrier(SB), $0
0x00f1 00241 (main.go:6) CALL runtime.mapaccess1_fast64(SB)
0x0114 00276 (main.go:7) CALL runtime.mapaccess2_fast64(SB)
0x0137 00311 (main.go:8) CALL runtime.mapdelete_fast64(SB)
0x0153 00339 (main.go:5) CALL runtime.gcWriteBarrier(SB)
0x0160 00352 (main.go:3) CALL runtime.morestack_noctxt(SB)
......
可以看到每个对map操作基本都有相应的同名调用函数。不过对map的初始化操作函数不是fastrand()函数,而是[runtime.makemap()](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L298-L336)函数(还有一个 runtime.makemap_small 函数)。fastrand()函数只是用来产生随机hash种子的。
注意:我们这里没有指定创建map的长度,runtime会根据是否指定这个字段做一些情况考虑。
// src/runtime/map.go
// makemap implements Go map creation for make(map[k]v, hint).
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
步骤:
- 计算指定的大小所需要的内容是否超出系统允许的最大分配大小
- 初始化hmap,并指定随机种子
- 通过
overLoadFactor(hint, B)函数找到一个能装下指定map大小个元素个数的最小B,从小到大开始循环B。刚开始map越小越好 - 开始对hash table进行初始化。如果
B==0则buckets 进行延时初始化操作(赋值的时候才进行初始化),如果B值特别大,则初始化需要一段时间,主要通过[makeBucketArray](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L338-L387)()函数实现
注意 makemap()函数返回的是一个指针,而makeslice()返回的是一个新的结构体,在参数传递的时候,是值复制,两者有差异,有些是引用的是同一个数组,有些不是。
// src/runtime/map.go
// makeBucketArray initializes a backing array for map buckets.
// 1<<b is the minimum number of buckets to allocate.
// dirtyalloc should either be nil or a bucket array previously
// allocated by makeBucketArray with the same t and b parameters.
// If dirtyalloc is nil a new backing array will be alloced and
// otherwise dirtyalloc will be cleared and reused as backing array.
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// For small b, overflow buckets are unlikely.
// Avoid the overhead of the calculation.
if b >= 4 {
// Add on the estimated number of overflow buckets
// required to insert the median number of elements
// used with this value of b.
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
if dirtyalloc == nil {
buckets = newarray(t.bucket, int(nbuckets))
} else {
// dirtyalloc was previously generated by
// the above newarray(t.bucket, int(nbuckets))
// but may not be empty.
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
if base != nbuckets {
// We preallocated some overflow buckets.
// To keep the overhead of tracking these overflow buckets to a minimum,
// we use the convention that if a preallocated overflow bucket's overflow
// pointer is nil, then there are more available by bumping the pointer.
// We need a safe non-nil pointer for the last overflow bucket; just use buckets.
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
初始化bucket
- 对于
b<4的话(桶的数量< 2^4),基本不需要溢出桶,这样就可以避免开销。对于b>4(桶的数量> 2^4)的话,则需要创建2^(b-4)个溢出桶。 - 数组分配通过函数
[newarray()](https://github.com/golang/go/blob/go1.15.6/src/runtime/malloc.go#L1209-L1218)实现,第一个参数是元素类型,每二个参数是数组长度,返回的是数组内存首地址
map读取
对于map中的赋值与修改原理是基本一样的,先找到位置,不管原来位置有没有数据直接存储新数据就可以了。
对于map的赋值操作,是由函数 [runtime.mapaccess1()](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L389-L450)和 [runtime.mapaccess2()](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L452-L508) 来实现的。两者的唯一区别就是返回值不一样,runtime.mapaccess1() 返回的是一个值,runtime.mapaccess2() 返回的是两个值,第二个值决定了key是否在map中存在。这点可以通过上面我们的 compile 结果中看出他们的区别。这里我们只介绍runtime.mapaccess1()
// src/runtime/map.go
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
// it will return a reference to the zero object for the elem type if
// the key is not in the map.
// NOTE: The returned pointer may keep the whole map live, so don't
// hold onto it for very long.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
runtime.mapaccess1()函数返回一个指定h[key]的指针,如果key不存在,则返回当前map值类型的zero值,注意永远也不会返回一个nil值。
返回的指针在map中是永远有效的,尽量读取完尽快使用并释放,不要长期持久。
步骤
- 判断h是否为nil或者h.count值是否为0,如果h为nil则表示未初始化,则可能panic,如果h.count=0,则表示map为空,则直接返回一个zero值。
- 考虑是否处于并发读写状态,否则产生panic
- 根据键key计算hash值
- 计算低B位的掩码
bucketMask(h.B),比如 B=5,那 m 就是31,低五位二进制是全1 - 计算当前bucket的地址
- 根据
h.oldbuckets是否为nil来判断是否处于扩容中,如果不是nil则表示当前map正处于扩容状态中。将m减少一半,重新计算当前key在 oldbuckets中的位置,如果oldbuckets没有全部迁移到新bucket的话(bmap.tophash的意义所在),则在oldbuckets中查找。 - 计算tophash,即高八位
- 真正开始查找key,外层for是循环bucket及溢出桶overflow,内层for是循环桶内的8个slot
- 如果
b.tophash[i] != top则表示当前bucket的第i个位置的tophash与当前key的tophash不同。这时分两种情况: 一种是当前的标识是emptyRest表示剩下的所有slot全是空,则直接结束当前bucket查找,继续下一个bucket重复此步骤(b = b.overflow(t)); 另一种则是继续查找下一个slot,直到8个slot全部查找完毕,然后再查找下一个bucket - 如果
b.tophash[i] == top,则根据键bucket的首地址+类型计算出字节长度*slot索引值 计算得出key的位置 - 判断同时bucket中的key与请求的key是否相等,如果相等的话,按取键的方法取出值,并返回,否则继续
- 如果在最后仍未找到key,则直接返回zero 值
key的定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
value 的定位公式
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
其中 dataOffset 表示key相对于bmap的偏移量,结构体如下
// src/runtime/map.go
// data offset should be the size of the bmap struct, but needs to be
// aligned correctly. For amd64p32 this means 64-bit alignment
// even though pointers are 32 bit.
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
所以键的地址=当前bucket的起始位置(unsafe.Pointer(b)) + key的偏移量(dataOffset)+当前slot索引值(i) * 每个键的大小(uintptr(t.keysize))
而对于值来讲,由于bmap.values在b.map.keys后面,所以要先将8个键的地址全部计算上才行,同样值类型也有自己的大小 t.elemsize
对于bucket的几种 状态码 如下
// src/runtime/map.go
// Possible tophash values. We reserve a few possibilities for special marks.
// Each bucket (including its overflow buckets, if any) will have either all or none of its
// entries in the evacuated* states (except during the evacuate() method, which only happens
// during map writes and thus no one else can observe the map during that time).
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
emptyRest 表示当前cell为空,并且它后面的所有cell也为空,包括溢出桶overflow。 emptyOne 表示当前cell为空。 evacuatedX 扩容相关,当前bucket的slot值迁移到了新桶的X部分,由于每次扩容时,都是两倍扩容,所以原来bucket中的8个slot值,有的被迁移到了新bucket的X部分,有的是Y部分(原来的1个桶变成2个桶,分别称作X和Y)。 evacuatedY 扩容相关,同上。 evacuatedEmpty 当前cell为空,且迁移完成。
minTopHash tophash最小值,如果在调用 tophash(hash) 时,计算出的值小于此值,则会加上此值( 代码)
map赋值
与赋值相关的函数是[mapassign](https://github.com/golang/go/blob/go1.15.6/src/runtime/map.go#L570-L683),根据key的不同底层调用相同类型的函数 ,常见的有
| key 类型 | 插入 |
|---|---|
| uint32 | mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer |
| uint64 | mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer |
| string | mapassign_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer |
我们这里主要介绍常用的mapassign函数。
函数原型
// src/runtime/map.go
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {}
步骤
- 检查是否处于并发模式,否则产生panic
- 进行 hash 值计算(同上)
- 检查bucket是否进行过初始化,否则调用
newobject(t.buckt)函数进行初始化,这点我们上面介绍过 - 检查map 是否处于扩容状态(
h.growing()),如果是则调用函数growWork(t,h,bucket)进行扩容工作 - 计算当前bucket的地址
- 计算
tophash,开始在bucket内通过for遍历出相应的位置,这点同上面的方法一样,双层for查找bucket,如果找到了再去overflow查找。找到则进行typedmemmove(t.key, k, key)更新并直接结束整个逻辑 - 如果在map里没有找到key,则判断如果map元素个数+1的话会不会触发扩容 扩容所必须的两个条件:
- 达到了最大装载因子
- 溢出桶是否过多 只要这两个其中的一个条件满足,则先进行扩容然后再重头开始。
- 到目前为止才算正式开始追加新的kv。要写入前必须要知道要写入的位置,有两个重要的变量,一个是inserti,另一个是insertk。如果此时inserti 为 nil的话,说明在上面第6步骤的时候遍历了所有的bucket和overflow也没有找到要插入的位置(bucket或overflow满了),则创建新的overflow,然后在新的overflow里计算出key和vlaue要存放的内存位置( 代码)
- 根据key和value的地址,写入新的值,并将当前map的元素个数加1。(需要特别注意的在这里并没有写入value,因为函数参数并没有传入值,所以返回的是一个存放v的内存地址,有了这个地址赋值就解决了)
总结:
触发map扩容的两个条件,一个是装载因子,另一个是overflow过多,对于overflow多少算多呢见下方说明。
map删除
与删除有关的函数为 mapdelete,原型
// src/runtime/map.go
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {}
根据 key 类型的不同,删除操作会被优化成更具体的函数:
| key 类型 | 删除 |
|---|---|
| uint32 | mapdelete_fast32(t *maptype, h *hmap, key uint32) |
| uint64 | mapdelete_fast64(t *maptype, h *hmap, key uint64) |
| string | mapdelete_faststr(t *maptype, h *hmap, ky string) |
步骤
- 判断map是否为nil或者根本就没有任何元素
- 检查是否并发模式
- 计算hash,双层for循环遍历查找key,找到位置后进行以下工作 将key位置写入nil或置零值 将value位置写入nil或置零值 将tophash位置置为 emptyOne 状态 判断当前key是不是bucket中的最后一个元素,如果是最后一个元素,且当前bucket还有overflow,而overflow的首个tophash[0] != emptyRest 说明已经没有元素可查找了,于是直接结束。否则判断当前key的下一个 tophash是不是emptyRest,如果不是的话,直接结束逻辑。后面利用for循环重置tophash 的状态为最合适的状态,以方便后期循环使用
map扩容
随着map元素的添加,有可能出现bucket的个数不够,导致overflow桶越来越多,最后变成了一个单向链表了,查找效率越来越差,最差的情况下可能会变成O(n)。这与我们期待的O(1)相反,所以golang为了解决这个问题,就需要对map中的元素进行扩容重新整理,以达到最优的效果。那么什么时候才需要扩容呢?
// src/runtime/map.go
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
这里有两个条件,只要满足其中一项就会进行扩容
- 当装载因子越过6.5的时候,这个是一个固定值( 查看说明)(代码)
- 当overflow 过多的时候 a. 当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B; b. 当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。 主要分界点就是15( 代码)
针对第一个条件,就是说元素太多,桶装不下了,立即进行扩容,添加1倍的桶,保证元素个数最多只能达到桶总容量的65%;
针对第二种情况一般是先是大量的添加元素,后来又删除了,再添加导致出现了太多的空的overflow,这样查找key的话,就需要遍历多个无效桶,效率大大下降,这时就需要重新对元素进行位置调整,类似于windows系统中的磁盘碎片整理一样,将overflow中的元素向前面的bucket迁移,以便下次查找数据时效率更高,这种情况我们称之为等量扩容。
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
// 装载因子>6.5
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
// 溢出桶过多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
虽然这里调用了 hashGrow() 函数,但它并不有真正的进行扩容,我们先看下它的源码
// src/runtime/map.go
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
//
// 申请2倍空间
bigger := uint8(1)
// 判断装载因子>6.5这个条件,否则就是由于overflow过多,此时申请的空间和原来的一样
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
// 调整hmap中的桶的指针指向,将原来桶变为旧桶,新桶为新申请的数组
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// 重点了解下 &^ 位运算符,其作用是按位置0
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// 提交grow操作
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0 // 迁移进度
h.noverflow = 0 // 溢出桶数量为0
// 将扩展举出桶指令同样和新旧桶一样进行指针指向变更
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
其中 hashGrow() 只是为扩容做的一些准备工作,而真正进行扩容的是 growWork() 和 evacuate() 函数。
函数 growWork() 只有在赋值和删除的过程中会出现,所以也只有这两个动作才会触发扩容动作。
我们再看看growWrok()源码
// src/runtime/map.go
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
// 确认迁移的老的bucket是我们正在使用的bucket
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
// 如果还是在迁移中,注再迁移一个bucket
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
从代码里可以看到,先是迁移我们正在使用的bucket,如果还有 bucket 没有迁移完的话,就再迁移一个bucket,也就是说一次最多可迁移两个bucket。
这里 h.oldbucketmask()是计算oldbucket的位置的,实现原理我们上面介绍过的,计算hash值的最低B位来决定用哪个bucket。
// src/runtime/map.go
// oldbucketmask provides a mask that can be applied to calculate n % noldbuckets().
func (h *hmap) oldbucketmask() uintptr {
return h.noldbuckets() - 1
}
下面我们重点关注 evacuate()函数,最复杂的工作就是由它来完成的。
// src/runtime/map.go
// evacDst is an evacuation destination.
type evacDst struct {
b *bmap // current destination bucket
i int // key/elem index into b
k unsafe.Pointer // pointer to current key storage
e unsafe.Pointer // pointer to current elem storage
}
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 计算 oldbucket 的地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
// 如果未迁移
if !evacuated(b) {
// TODO: reuse overflow buckets instead of using new ones, if there
// is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations.
// 由于是两倍大小扩容,这里x和y分别代表新的两个bucket
// evacDst 是迁移目的结构体,主要有四项数据,分别是要接收新数据的桶、值所在桶内的索引位置、map键和map值的指针地址
var xy [2]evacDst
// 获取目标 x bucket 的地址
x := &xy[0]
// 设置当前要迁移到的新桶相关信息
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 如果不是等量扩容的话
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
// 获取目标 y bucket 的地址,和上面x一样
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 使用双层for循环进行数据迁移
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
// 如果当前tophash索引位置的元素标记为empty,即为emptyRest或emptyOne,说明根本就没有内容要迁移,可以直接标记为迁移完成状态 evacuatedEmpty
if isEmpty(top) {
// 设置旧桶位置为迁移完成标记 evacuatedEmpty
b.tophash[i] = evacuatedEmpty
continue
}
// 位置标记非法,好像永远也不会出现这个情况
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
// iterator!=0 说明有协程正在遍历当前map
// !t.key.equal(k2,k2) 表示同一个key计算出为的hash值不一样
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// If key != key (NaNs), then the hash could be (and probably
// will be) entirely different from the old hash. Moreover,
// it isn't reproducible. Reproducibility is required in the
// presence of iterators, as our evacuation decision must
// match whatever decision the iterator made.
// Fortunately, we have the freedom to send these keys either
// way. Also, tophash is meaningless for these kinds of keys.
// We let the low bit of tophash drive the evacuation decision.
// We recompute a new random tophash for the next level so
// these keys will get evenly distributed across all buckets
// after multiple grows.
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
// 如果目标桶内元素索引值=8,即超出桶内最大元素个数8,则新建溢出桶,并将桶内cell索引值置为0
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 设置tophash值
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 进行数据迁移操作
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 索引位置下移一位,即下次存储数据的cell位置
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// Unlink the overflow buckets & clear key/elem to help GC.
// 如果oldbucket没有协程在使用的话,则帮助gc把bucket清除掉
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
// 清除bucket 的 key,value 部分,保留 tophash 部分,指示搬迁状态
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
// 如果当前迁移的bucket 就是当前的 oldbucket
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
函数advanceEvacuationMark()源码
// src/runtime/map.go
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// 更新当前map的迁移进度
h.nevacuate++
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 一次标记1024个
stop := h.nevacuate + 1024
// 如果标记个数超出了实际oldbucket的个数,则使用oldbucket的数量值
if stop > newbit {
stop = newbit
}
// 循环标记bucket
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 当前迁移桶等于oldbucket的总数量,即迁移完毕
if h.nevacuate == newbit { // newbit == # of oldbuckets
// Growing is all done. Free old main bucket array.
// 重置oldbuckets为nil,即表示oldbuckets 迁移完毕
h.oldbuckets = nil
// Can discard old overflow buckets as well.
// If they are still referenced by an iterator,
// then the iterator holds a pointers to the slice.
// 如果h.extra != nil 说明保存的kv中没有指令,使用了slice存储,所以这里也需要同时清除oldoverflow
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}
对于map 的扩容,主要分两种情况,一个是等量扩容,另一种是非等量扩容,什么意思呢?
所谓等量扩容是指原来是一个bucket,虽然扩容的时候创建了两个新的bucket,但使用的时候只使用了其中一个bucket,另一个没有使用,所以这种情况下的扩容是直接将原来oldbucket中的元素直接迁移到新 bucket中的x桶就可以了。
而非等量扩容就是将原来一个bucket 中的内容迁移到新的两个bucket中。
我们知道每个bucket 最多只有8个元素,迁移需要一个一个的迁移,每迁移完一个元素,都需要将当前cell作个标记,表示当前位置的元素已经迁移完成,对于等量扩容和非等量扩容两者是有些细微的差别的。我们先看一下等量迁移。
对于等量扩容来说,由于bucket是1对1的迁移,况且都迁移到了x桶,所以oldbucket中每个cell在迁移后被标记为evacuatedX,表示当前oldbucket中的元素全部被迁移到了x桶了。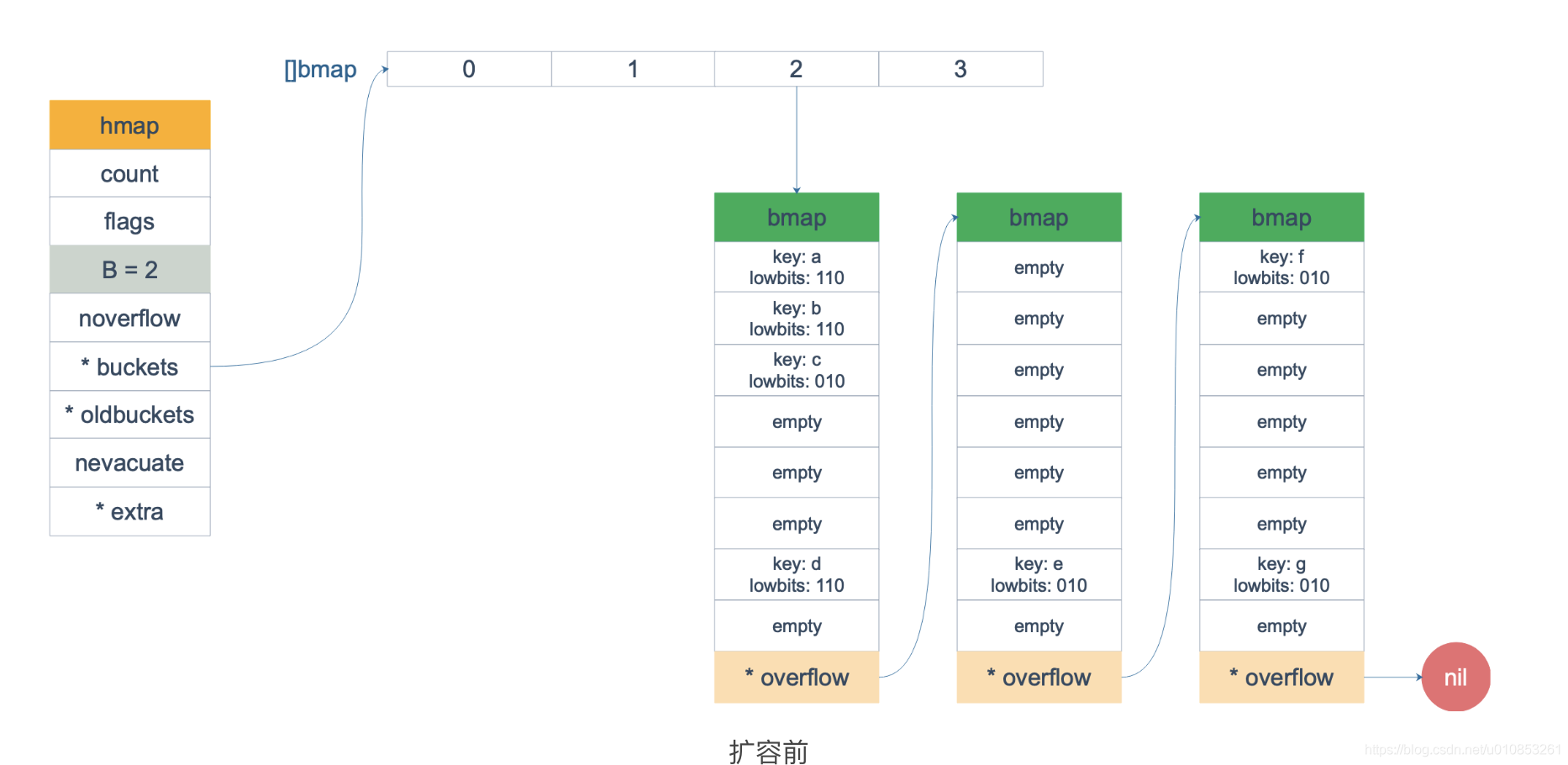
经过等量扩容后,原来的overflow消失了,所有元素都放在了同一个bucket,节省资源的同时查询效率也提高了。是不是有点像widows 的磁盘碎片整理。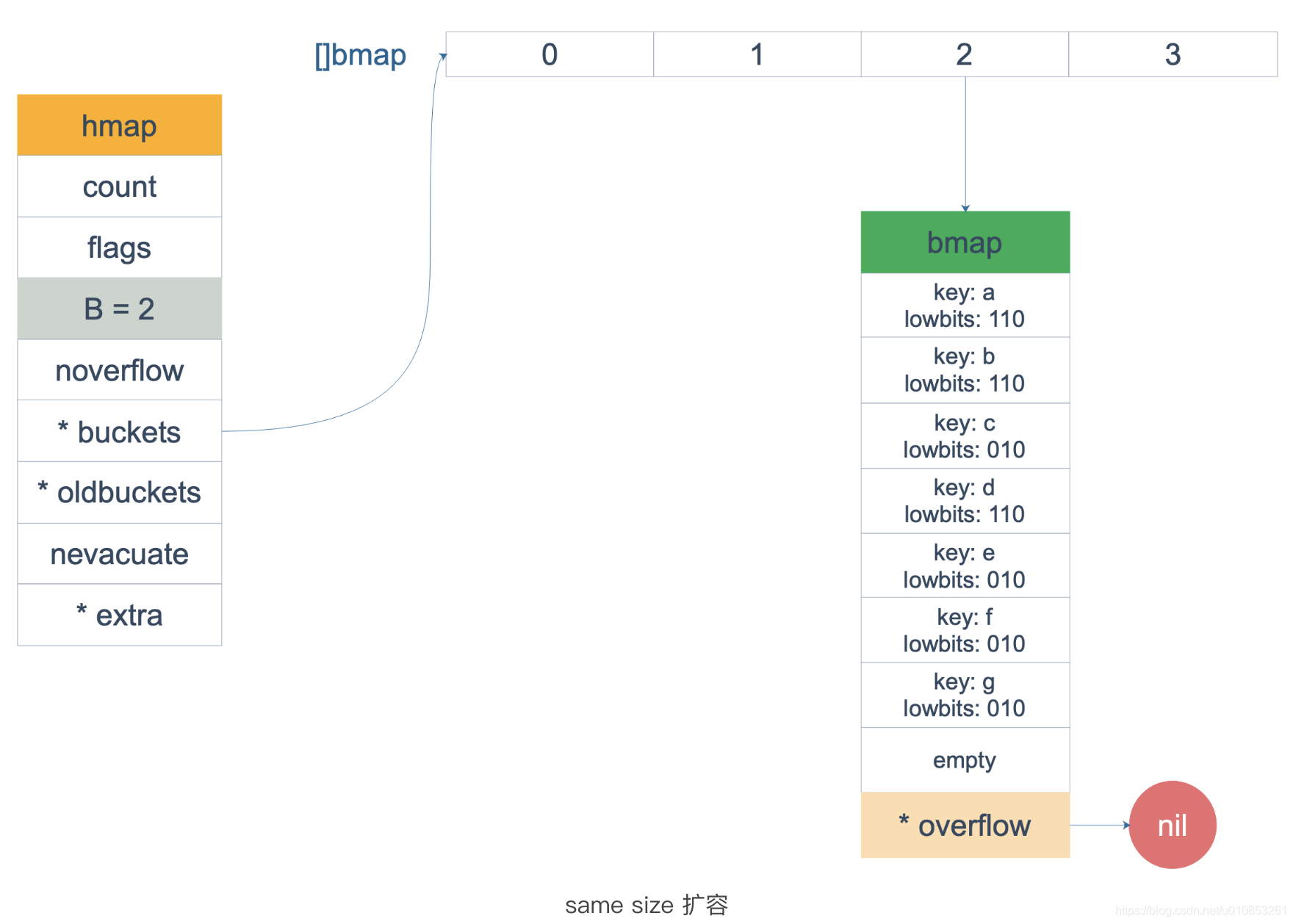 等量扩容后
等量扩容后
而对于非等量扩容,bucket的关系就是1对2了,oldbucket 中的元素有可能经过rehash后,被迁移到了x桶,也有可能被迁移到了y 桶。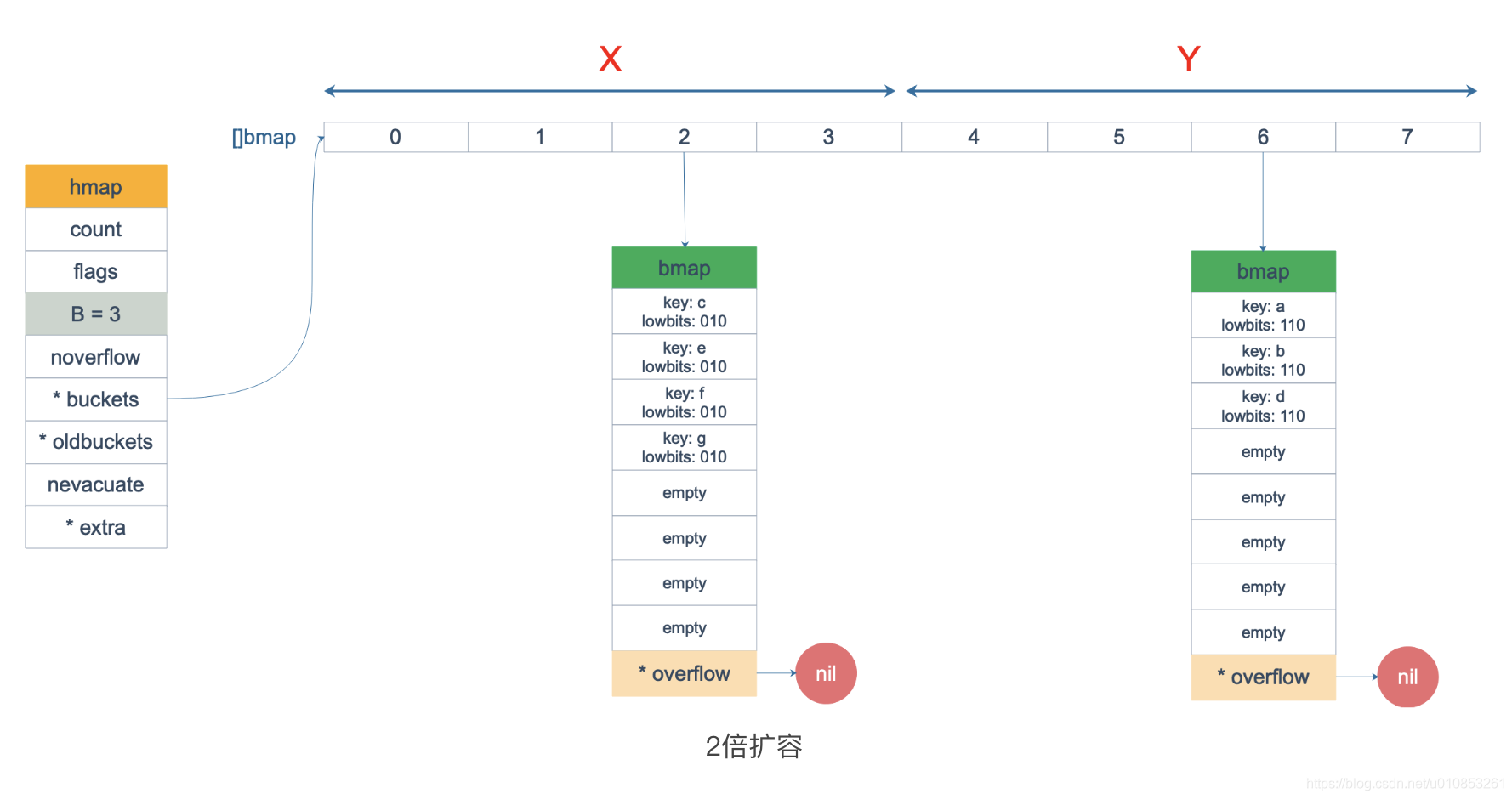 map非等量扩容
map非等量扩容
如果是被迁移到了y桶的话,则标记为evacuatedY,否则就是evacuatedX。
如果oldbucket中的元素为空(emptyRest或emptyOne),即未存储任何元素或者原来存储过后来删除了,则需要标记为evacuatedEmpty。
经过迁移后,我们发现元素在oldbucket中的存储顺序,到新的bucket中发生了变化。如odlbucket里有8个元素(1-8),遍历打印的时候,会打印12345678。后来分成了两个bucket, 其中3/4/8 放在了x桶,1/2/5/6/7放在了y桶,那么这时遍历打印的话,则是遍历打印x桶,然后是y桶,最后打印34812567,与原来的顺序不一样了,这正是我们平时所说的对map的遍历并不保证一定的顺序的。
当然在源代码里起始位置也是随机定位的,先是随机选择一个bucket,然后再随机选择一个cell位置,开始往后遍历查找,当达到最后bucket的最后一个元素的时候再从第一个bucket查找,直到遍历到当前元素等于起始元素为止。官方是为了引起我们的注意因此故意这样设计。所以就算你是硬编码写死的map不进行删除或添加,打印的值也是随机的。
由于map内部是按bucket迁移的,每次最多迁移两个bucket,所以在遍历数据的时候也有些复杂,即可考虑新bucket的数据,也要考虑oldbucket中的数据。有些oldbucket中的数据被分分到两个新bucket中了,导致要考虑的情况要多一些。等有时间了再单独写写这一块的实现逻辑。
最后,当所有数据都迁移完成后,还需要将oldbucket清除,直接通过设置 h.oldbuckets为nil 即可,记得还有一个mapextra.oldoverflow。
在扩容过程中,有一个注意事项,见官方说明
// If key != key (NaNs), then the hash could be (and probably // will be) entirely different from the old hash. Moreover, // it isn’t reproducible. Reproducibility is required in the // presence of iterators, as our evacuation decision must // match whatever decision the iterator made. // Fortunately, we have the freedom to send these keys either // way. Also, tophash is meaningless for these kinds of keys. // We let the low bit of tophash drive the evacuation decision. // We recompute a new random tophash for the next level so // these keys will get evenly distributed across all buckets // after multiple grows.
在进行hash计算的时候,有一种key,它每次经过hash计算的时候,得出的结果都不一样,这个key就是math.NaN(),表示 Not a Number,类型是 float64。一旦使用此key进行存储后,几乎无法正确读取出来值,只有在遍历的时候才会读取到此值。为了解决这个问题,官方采用了使用tophash的最低位来决定是放在x还是y,如果是0则放在x,否则放在y。
总结
- map不是并发安全的,所以在源码里有大量的代码判断
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
在赋值时会设置map处于协程写的状态
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
- 遍历map是无序的,因为随着元素的添加和删除会进行扩容,元素位置会发生变化
参考
- https://blog.csdn.net/u010853261/article/details/99699350
- map 的底层实现原理是什么
- https://studygolang.com/articles/22236
- https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-hashmap/